-
Jane Austen 소설 속 Term FrequencyR/TextMining 2019. 10. 21. 17:59
install.packages("tidytext")
install.packages("tidyverse")
install.packages("janeaustenr")
library(tidytext)
library(tidyverse)
library(janeaustenr)# 단어의 빈도를 구함
janeaustenr::austen_books() %>%
tidytext::unnest_tokens(output = word, input = text) %>%
dplyr::count(book, word, sort = TRUE) %>%
dplyr::ungroup() -> book_words# 소설별로 단어 빈도의 합계를 구함
book_words %>%
dplyr::group_by(book) %>%
dplyr::summarise(total = sum(n)) -> total_words# 데이터 합치기 : left join
book_words <- dplyr::left_join(book_words, total_words)# 단어를 합계로 나눈 값을 기준으로 히스토그램 작성
book_words %>%
ggplot2::ggplot(mapping = aes(x = n/total, fill = book)) +
ggplot2::geom_histogram(show.legend = FALSE) +
ggplot2::xlim(NA, 0.0009) +
ggplot2::facet_wrap(~book, ncol = 2, scales = "free_y")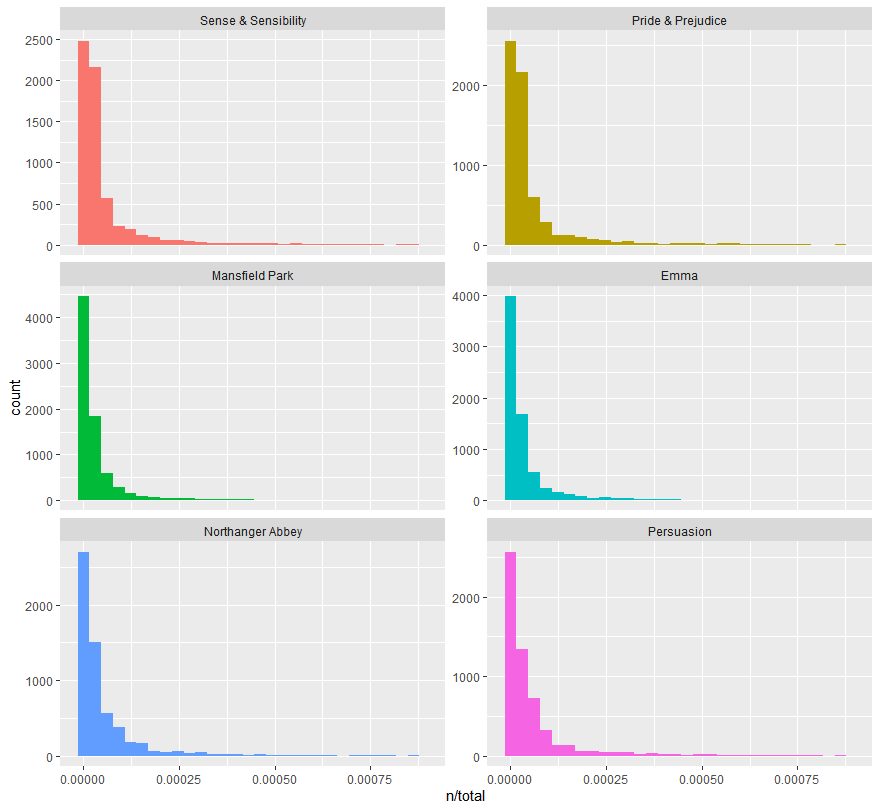
[ 출처] R로 배우는 텍스트마이닝, 줄리아 실기/데이비드 로빈슨 지음, 박진수 옮김, Jpub, p38~39
'R > TextMining' 카테고리의 다른 글
R and BERT (0) 2019.10.29 문재인 대통령 평양 연설문에 대한 Word Cloud 작성하기 (0) 2019.10.24 감성분석(Sentiment Analysis)을 위한 패키지들(packages) (1) 2019.10.21 word cloud : 부정적인 단어와 긍정적인 단어 표현하기 (0) 2019.10.21 감성기술의 5대 난제 (0) 2018.11.27